Testing is a skill. While this may come as a surprise to some people it is a simple fact. - Fewster and Graham
What is XPath?
XPath stands for XML Path Language. It provides different types of expressions, or queries, that are used to navigate through XML and HTML documents and select a node or a set of nodes.
XPath is written in a path-like syntax that resembles the path in a traditional file system (hierarchical or tree-like structure):
xpath_syntax = //tagname[@attribute='Value']
xpath_example = //input[@id='new-todo']
When you can’t make use of other locators such as ID, Class, and so on, XPath will come in handy to locate the element because it will always be available.
Sometimes it might be rather long and not very pretty. However, you should avoid using this type of XPath, called absolute XPath, since it is quite brittle.
/html/body/div[2]/div[1]/h4[1]/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]
Briefly about nodes
When reading about XPath and XML you will often come across the term node.
An XML document is treated as a tree of nodes in which the nodes are in a hierarchical relationship to each other. Each node is an XML element enclosed within an opening < and a closing > tag, such as:
<element></element>
Types of nodes
There are seven types of nodes:
- Root
- Element
- Text
- Attribute
- Comment
- Processing instruction
- Namespace
XML file example:
<?xml version="1.0" encoding="UTF-8"?>
<library>
<book>
<title lang="en">The Lord of the Rings</title>
<author>J. R. R. Tolkien</author>
<year>1954</year>
</book>
</library>
In the example above:
<?xml version="1.0" encoding="UTF-8"?> is a processing instruction used to instruct the application how to read the document
<library> is the root (the topmost) element node
<author> is an element node
lang="en" is an attribute node
Relationships between the nodes
As mentioned, the nodes are in a hierarchical relationship to each other. The terms used to describe that relationship are parent, child and sibling. Except for the root, every node in the hierarchy has exactly one parent node. A node can have any number of child nodes. The nodes that have the same parent are called siblings.
The terms that could also be used are ancestor and descendant. The parent of a node or a parent of a parent is called an ancestor. Similarly, a child of a node, or a child of a child node is a descendant.
Using the XML example above:
<book> is the parent of <title>, <author> and <year>
<title>, <author> and <year> are siblings
<title> is the first child of <book>
<year> is the last child of <book>
The ancestors of <author> are <book> and <library>
The descendants of <library> are <book>, <title>, <author> and <year>
Types of XPath
There are two types of XPath:
- Absolute XPath
- Relative Xpath
Absolute XPath
- Starts with a single slash (/) which means it starts from the root element
- It directly locates an element
- It is fragile
Example: /html/body/div[2]/div[1]/h4[1]/b/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]
Relative XPath
- Starts with a double slash (//) which means it starts from anywhere in the document
- Shorter and easier to read compared to the absolute path
- It is less fragile compared to the absolute path
Example: //img[@id="profile_image"]
XPath Axes
An axis (plural axes) represents a relationship between the nodes, i.e. axes are used to locate a node relative to the current (context) node on the tree.
There are 13 different axes in the XPath:
- ancestor - represents all ancestors of the current node
- ancestor-or-self - represents the current node and all its ancestors
- attribute - represents the attributes of the current node. It can be abbreviated with the @ sign
- child - represents the children of the current node
- descendant - represents all children (and all their children) of the current node, and all of their children
- descendant-or-self - represents the current node and all its descendants
- following - represents all the nodes that appear after the current node, except any descendant, attribute, and namespace nodes
- following-sibling - represents all the nodes that have the same parent as the current node and appear after the current node in the source document
- namespace - represents all namespace nodes of the current node. If the current node is not an element node, the result will be empty
- parent - represents the single node that is the parent of the current node. It can be abbreviated as two periods (..)
- preceding - represents all the nodes that precede the current node in the document except any ancestor, attribute, and namespace nodes
- preceding-sibling - represents all the nodes that have the same parent as the current node and appear before the current node in the source document
- self - represents the current node itself. It can be abbreviated as a single period (.)
Examples
Select all book nodes that are children of the current node:
//child::book
Select the lang attribute of the current node:
//attribute::lang
Select all children nodes of the current node:
//child::*
Select all text node children of the current node:
//child::text()
Select the first child node from the list within class todo-list:
//*[@class='todo-list']//child::li[1]
XPath functions
Sometimes writing a simple XPath won’t be enough. XPath includes a bunch of built-in functions for strings, numbers, booleans, node manipulation, and so on. You can use those functions to write more specific XPaths.
Some of the more useful ones are:
- Contains
- Starts with
- Text
Contains
contains is very useful when you’re trying to get the constant part of a dynamic element.
Select the todomvc.com link in the DOM:
//*[contains(@href,'todomvc.com')]
Select the text containing “here” in the DOM:
//*[contains(text(),'here')]
Starts with
starts-with checks the starting text of an attribute.
Select the image element whose alt text starts with "Profile":
//img[starts-with(@alt,'Profile')]
Text
text locates the element based on its text.
Select the element with the text "About":
//span[text()='About']
How to use Chrome DevTools to find XPath
Writing XPath is sometimes tricky. It is useful to know your way around DevTools to help you with finding the right XPath. TodoMVC app was used as an example.
Press Fn + F12 to open DevTools
Open Elements tab
While the Elements tab is active, press Cmd + F to open the search field
Type in an XPath selector
- If there is a match, the element(s) will be highlighted in the DOM
Examples from the images below
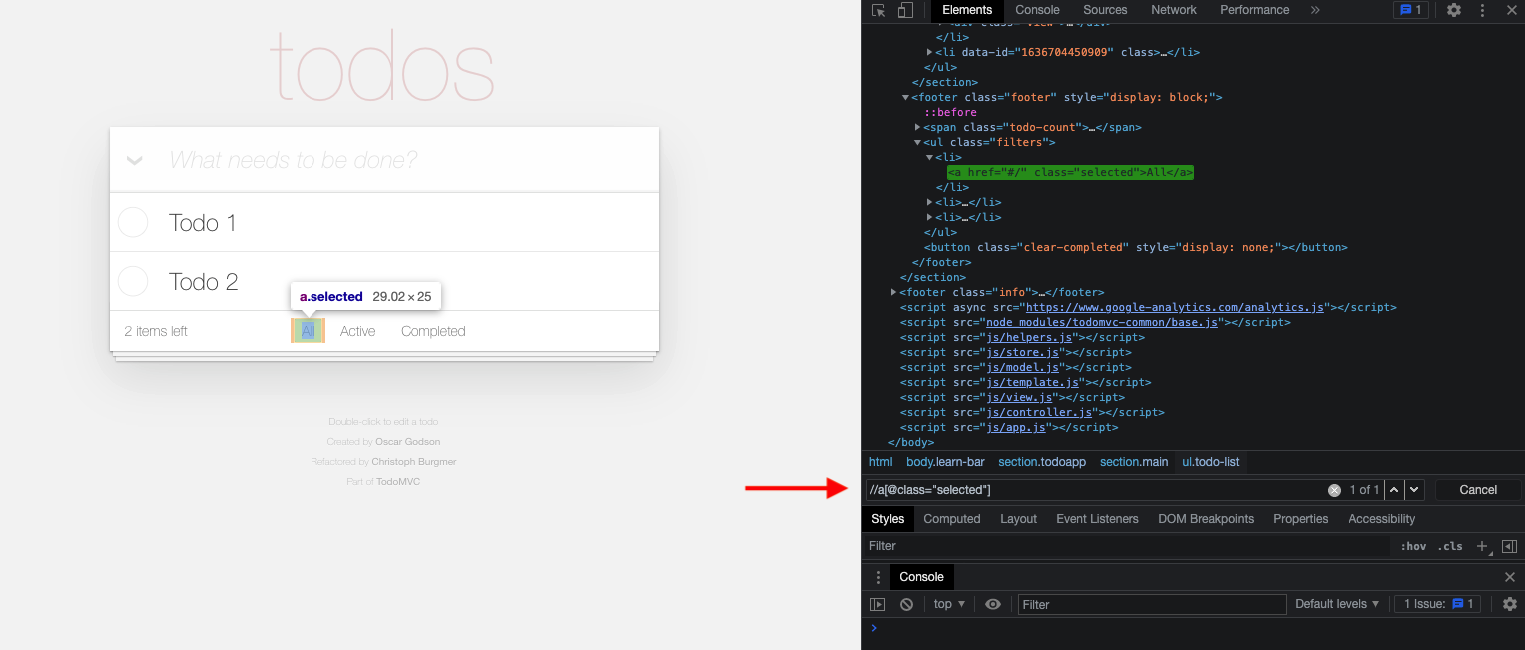
Select the All button:
//a[@class="selected"]
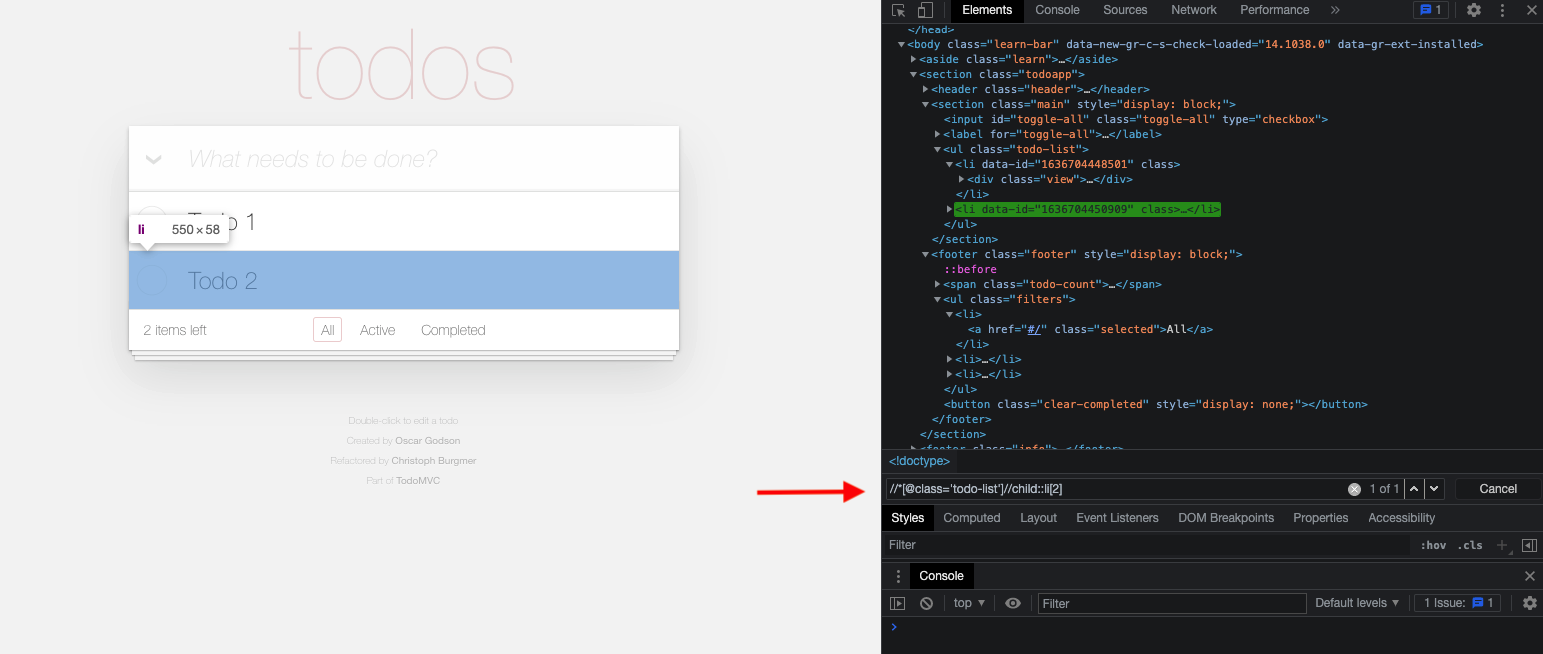
Select the second todo element:
//*[@class="todo-list"]//child::li[2]
Additional resources
For more details and examples take a look at the following resources: