Motivation
Although the characters encoding issue is not an issue with NextJS but React (check more details here), you can encounter this if you have static pages that have some HTML entities in the page content - e.g. ampersand (&) in query parameters.
These HTML entities will not be encoded by default, which will result in incorrect content. This will pose an issue mostly for crawlers.
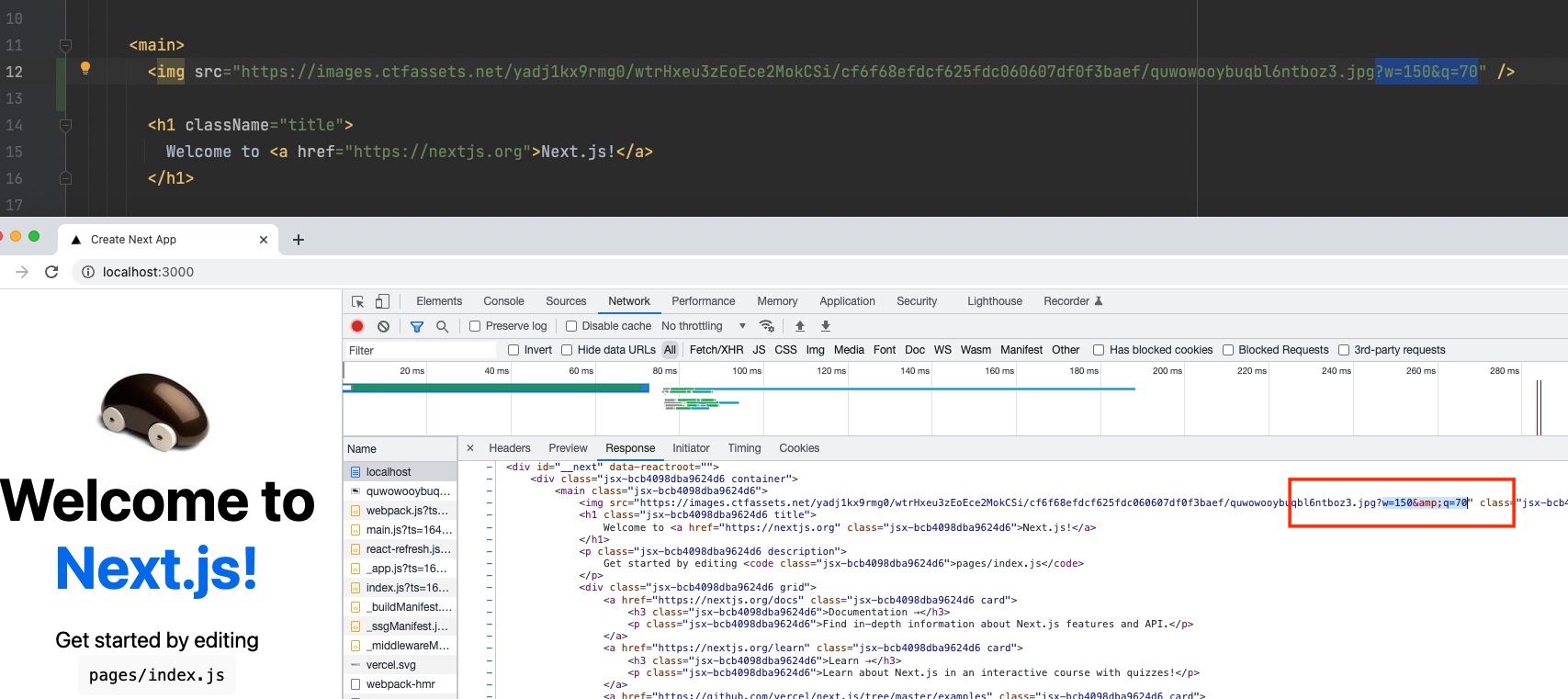
This can be fixed by adding a custom decode method in the _document file.
Disclaimer:
- Check if this issue is still happening
- Check if the fix is needed
- Always be cautious when changing default Next.js custom document configurations
To prepare for React 18, we recommend avoiding customizing getInitialProps and renderPage, if possible.
Implementation
If you do not have the _document file in the pages folder, create a file with the default content (copy all except gIP in _document) and:
- install the
html-entitiespackage (https://github.com/mdevils/html-entities) - import the
html-entitiespackage
import { decode } from 'html-entities';
- add the gIP implementation in the class
static async getInitialProps(ctx) {
const initialProps = await Document.getInitialProps(ctx);
// based on https://github.com/vercel/next.js/issues/2006
return {
...initialProps,
html: initialProps.html.replace(
/(href|src|srcSet)="([^"]+)"/g,
(match, attribute, value) => `${attribute}="${decode(value)}"`
),
};
}
- add or change regex properties to handle more cases
The above code searches and replaces all href, src and srcSet attributes in all pages with decoded characters.
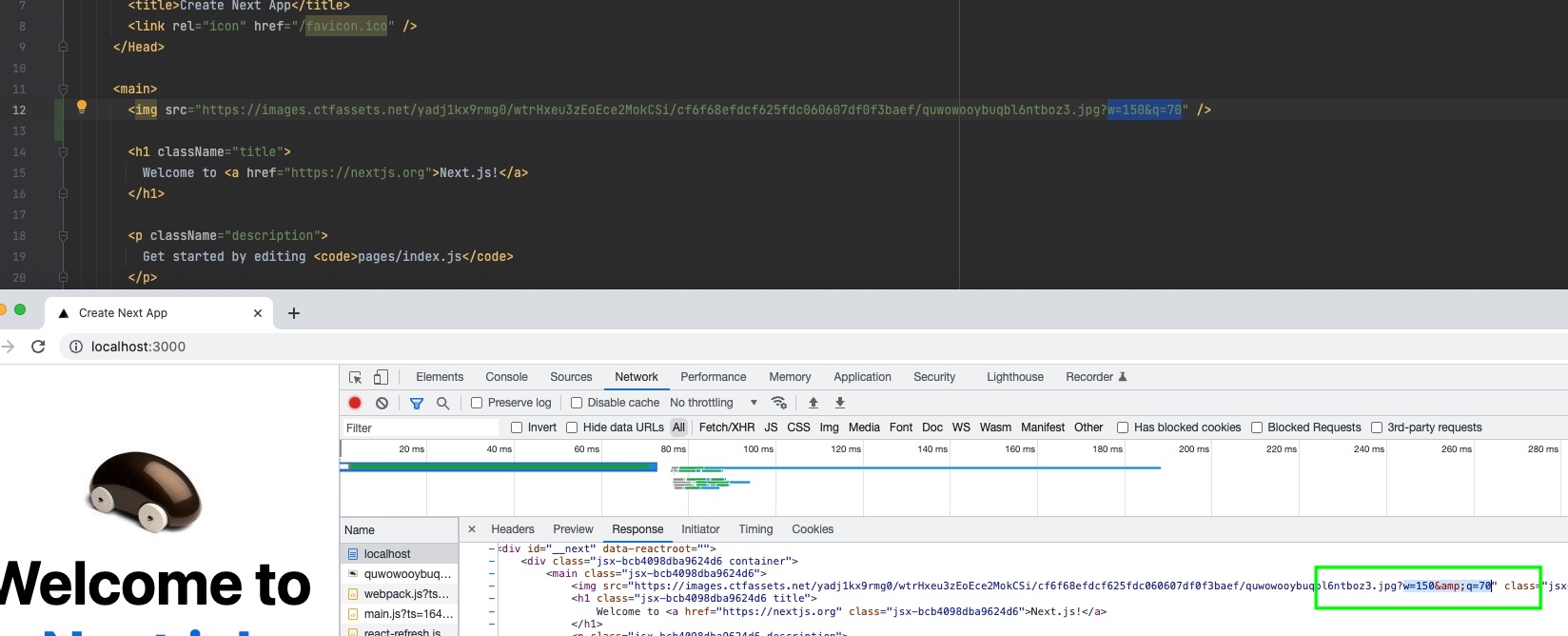
Conclusion
If you need to encode HTML entities, the proposed solution will work well. There is no need to add this by default.