







We explore non-copyable types, Swift’s game-changing feature that boosts performance and safety for resource-heavy code. Find out how non-copyable types work, why they matter, and how they can optimize your workflow for critical use cases.
Version 5.9 marked a big step in Swift’s evolution toward a high-performance and ergonomic programming language. Along with new ownership modifiers, the release introduced non-copyable types – instances that always maintain unique ownership, ensuring they cannot be copied.
Although we likely won’t see non-copyable types widely used in common codebases, they enable important features like Swift-native Atomics and Locks. Non-copyable types also offer significant benefits in terms of safety and performance, but their somewhat esoteric syntax and niche use cases can make them difficult to grasp.
In this article, we’ll take a closer look at what non-copyable types bring to the table, break down their complexities, and explain how they fit into Swift’s evolving ecosystem. Even if you don’t expect to use non-copyable types regularly, learning how they work will give you a better understanding of Swift’s growing capabilities.
Copyability in Swift
The concept of copyability represents one of the main distinguishing traits between value and reference types in Swift. This distinction is highlighted early in The Swift Programming Language book:
A value type is a type whose value is copied when it’s assigned to a variable or constant, or when it’s passed to a function. (source)
Unlike value types, reference types are not copied when they’re assigned to a variable or constant, or when they’re passed to a function. (source)
This distinction often plays a crucial role in choosing the right construct for solving a particular problem. However, the introduction of non-copyable types gives us a new perspective on copyability.
Consider the following code sample:
var x: Test? = Test()
let y = x
x = nil
In this example, we deliberately avoid specifying what Test is. However, regardless of its exact definition, the compiler must guarantee that the variable y remains valid even after x is set to nil.
How can a compiler do that? Typically, it handles it through one of two mechanisms:
1
If Test is a simple (bitwise-copyable) struct, its bytes are copied to a separate memory location.
2
If Test is a class, the instance is retained through reference counting.
These two approaches demonstrate different notions of copyability, which have been explicitly formalized with the introduction of the Copyable protocol. Both mechanisms allow programmers to pass values and references around safely and efficiently, while the compiler can use one of these operations to ensure safe code execution.
Implicit conformance is not a new idea in Swift. We’ve already seen implicit Sendable conformance, and there is also a proposal for adding default conformance to the Escapable protocol.
Why we need non-copyable types
For over a decade, Swift’s ever-present copyability has served us well. But as Swift evolves into a true general-purpose programming language, and especially with growing ambitions in the embedded systems space, new demands for safety and performance have emerged. These requirements bring forth new code idioms that call for advanced features like non-copyable types, designed specifically for performance-critical and correctness-sensitive code.
For example, some real-world scenarios where performance and correctness are critical include:
- Database connections
- Database cursors
- Transactions
- Network connections
- Audio buffers
- Wrapping C libraries
In these cases, specific state transitions can invalidate instances, making ownership controls essential for ensuring safe and reliable code.
Let’s explore these two key aspects in more detail.
Optimizing performance
In a previous article on ownership in Swift, we explored the concept of borrowing and consuming parameter modifiers, both aimed at optimizing performance-critical code. Non-copyable types take this a step further by providing even stronger guarantees, requiring us to explicitly define ownership conventions when passing an instance of a non-copyable type.
There are two main sources of performance improvements when using non-copyable types:
- Inline storage: non-copyable types are stored inline with the containing type, which eliminates the need for separate memory allocations
- No reference counting: since non-copyable types don’t rely on reference counting, the overhead associated with tracking references is completely removed
Consider the following code:
func test(_ numbers: [Int]) {}
let numbers = (1...10000000).map { $0 }
test(numbers)
Since Array is a copy-on-write (CoW) data type and no mutations are happening, the large array won’t be copied – this is an important optimization for most common use cases.
However, there’s a hidden performance cost: reference counting. As a CoW data type, the underlying array buffer must be reference counted so that Swift’s runtime knows when an actual copy is necessary.
While a single retain might seem negligible, when this code is invoked in a loop, the performance impact becomes more significant – a point we’ll explore further in the case study.
Ideally, we’d have a NonCopyableArray type that would allow the compiler to reject code that might trigger expensive copies.
Maximizing correctness
Non-copyable types also improve code correctness by enforcing unique ownership and preventing invalid states. For example, consider the following code (the ~ indicates non, which we’ll explore in more detail later):
struct SingleUseToken: ~Copyable {
private let token: String
init(token: String) {
self.token = token
}
consuming func use() -> String {
return token
}
}
func run() {
var token = SingleUseToken(token: "1234")
print(token.use())
print(token.use()) ❌ `token` consumed more then once
}
By declaring SingleUseToken as ~Copyable, we ensure that the compiler rejects any invalid code where a token is consumed more than once.
This explicit state management requires unique ownership, and the compiler enforces the following:
There can’t be multiple variables pointing to the same value.
For example:
func multipleVariables() {
var token = SingleUseToken(token: "1234")
var tokenReference = token
print(token.use()) ❌ `token` consumed more then once
}
The message above is somewhat confusing, but the token is not valid anymore when we assign (move) it to tokenReference.
To summarize, non-copyable types represent a new tool in the Swift type system:
| Unique resource | Unique ownership | Inline storage | |
struct, enum | ❌ | ❌ | ✅ |
class, actor | ✅ | ❌ | ❌ |
~Copyable | ✅ | ✅ | ✅ |
The syntax of non-copyable types
Swift’s esoteric choice of syntax for non-copyable types has sparked considerable debate within the Swift community, and it’s worth understanding the rationale behind it.
The naming of this feature is somewhat unfortunate and has also caused some confusion, especially when used in Swift’s generics system. The main challenge was to establish a syntax that clearly communicates the suppression of default Copyable conformance.
The initial pitch for this feature proposed the following syntax:
@noncopyable
struct Test {}
However, this approach didn’t integrate well with Swift’s generics system, so the language designers adopted a different method, using a protocol constraint instead.
Typically, protocols in Swift describe functionality that adds behavior to types. In the case of non-copyable types, the situation is reversed – functionality is removed from the type. Therefore, Swift needed a syntax that allows a type to suppress the default Copyable conformance.
Swift’s ~ operator is not generally applicable and only works on specifically chosen protocols. Nevertheless, it is a more flexible and powerful tool because it allows Swift to suppress other conformances in the future (e.g. BitwiseCopyable).
Interestingly, Swift is not alone in adopting this approach. For example, Rust uses the ? operator for a very similar purpose.
Ownership modifiers
New ownership modifiers are a key requirement for the implementation of non-copyable types. While for regular types these modifiers serve as optional guardrails, they are mandatory for non-copyable types because these types enforce unique ownership. This means developers must be explicit when passing them around, clearly defining how ownership rules are transferred or borrowed.
Consuming ownership
When a function takes ownership of a non-copyable type, we mark the parameter as consuming. This transfers ownership to the function, invalidating the original owner:
func use(token: consuming SingleUseToken) {}
let token = SingleUseToken()
use(token: token)
token.use() ❌ `token` consumed more then once
Some operations, like variable assignments, have default consuming semantics:
let token = SingleUseToken()
let consumedToken = token
token.use() ❌ `token` consumed more then once
Borrowing ownership
If a function requires a parameter of a non-copyable type only temporarily, we mark the parameter as borrowing. This indicates that the original ownership is not invalidated and that the function cannot consume the parameter in any way.
func borrow(token: borrowing SingleUseToken) {}
let token = SingleUseToken()
use(token: token)
token.use() allowed
func borrow(token: borrowing SingleUseToken) {
token.use() `token` is borrowed and cannot be consumed
}
let token = SingleUseToken()
borrow(token: token)
The inout modifier
Before looking into how the inout modifier behaves with non-copyable types, it’s helpful to review what inout does:
In-out parameters are passed as follows:
- When the function is called, the value of the argument is copied.
- In the body of the function, the copy is modified.
- When the function returns, the copy’s value is assigned to the original argument.
For non-copyable types, things are a bit different. If a function consumes an inout argument, the compiler will issue a warning, indicating that the inout argument must be reinitialized (since it cannot be copied back after consumption):
func `inout`(token: inout SingleUseToken) {
token.use() ❌ Missing reinitialization of inout parameter `token` after consume
}
let token = SingleUseToken()
inout(token: token)
Mutating functions
A mutating function implicitly takes the self argument as inout, which means the same rules apply as for explicit inout arguments:
extension SingleUseToken {
mutating func useAndUpdate() {
self.use() ❌ Missing reinitialization of inout parameter `self` after consume
}
}
The discard operator
Although non-copyable types are value types, their unique ownership makes deinit relevant.
You can declare a deinit for non-copyable types, just as you would for classes:
struct SingleUseToken {
deinit {
UserDefaults.standard.set(false, "token-used")
}
}
However, there are scenarios where you may want to prevent deinit from being called in certain code paths:
struct SingleUseToken {
consuming func use() -> String {
let token = token
UserDefaults.standard.set(true, "token-used")
discard self
return token
}
deinit {
UserDefaults.standard.set(false, "token-used")
}
}
If we didn’t discard self, the deinit would be called and token-used would be incorrectly set to false.
Non-copyable generics
Swift’s type hierarchy has traditionally assumed that types are copyable, which is reflected in the interaction between structs, enums, and classes:

However, the introduction of non-copyable types presents a new challenge: how do these types fit into the existing hierarchy?
At first glance, one might assume that non-copyable types could be considered subtypes of regular structs and enums. However, this isn’t possible because these types are inherently copyable. Another idea might be to place them as subtypes of Any, but unfortunately, this approach also fails since Any is implicitly Copyable.
Consider the following example:
struct Test: ~Copyable { }
let test = Test()
test as Any ❌ Noncopyable type 'Test' cannot be erased to copyable existential type 'Any'
Therefore, non-copyable types do not fit into the existing hierarchy but form their own type hierarchy instead.

However, having two independent type hierarchies makes it really challenging to write generic code. A simple example illustrates this issue:
struct Test: ~Copyable { }
func generic<T>(t: T) {}
generic(Test()) ❌ Noncopyable type 'Test' cannot be substituted for copyable generic parameter 'T'
In this case, the generic type parameter T assumes copyability, as it is a subtype of Any. Consequently, a type from the non-copyable hierarchy can’t be passed in.
We could employ a workaround here, writing an alternative function that accepts non-copyable types. However, this approach makes non-copyable types feel like second-class citizens in Swift’s type system.
The issue is even worse if you consider that you can’t use non-copyable types with Optional:
struct Test: ~Copyable { }
let test = Optional<Test>.none ❌ Noncopyable type 'Test' cannot be used with generic type 'Optional<Wrapped>'
Before delving into the new type hierarchy, it is important to clarify the meaning of ~Copyable.
~Copyable suppresses the implicit conformance to the Copyable protocol.
This means that when a type is marked as ~Copyable, the compiler is not allowed to insert any copy operations for that type.
Here’s what this means for generic code constrained to ~Copyable:
func generic<T: ~Copyable>(t: T) { ❌ Parameter of noncopyable type 'T' must specify ownership
}
First of all, we need to specify ownership, as the compiler needs to understand which operations are allowed within the function.
struct NC: ~Copyable { }
struct CO { }
func generic<T: ~Copyable>(t: borrowing T) {}
generic(Test()) ✅ allowed
generic(CO()) ✅ allowed
Once we do that, we can use generic functions both with ~Copyable and Copyable types.
This way, Copyable types are effectively a subtype of ~Copyable, as Copyable adds new functionality to the conforming type.
Finally, the new type hierarchy can be illustrated as follows:

Non-copyable or maybe-copyable?
At first glance, it may seem strange that we can use a copyable type in place of a non-copyable one in generic code. This is where the naming of the feature can be confusing. In generic code, we are not strictly dealing with non-copyable types, but rather maybe-copyable types.
In a way, the distinction is contextual:
- Our Test struct is non-copyable – the compiler will prevent any attempt to copy it
- A generic parameter T constrained by ~Copyable is maybe-copyable, meaning that a given parameter cannot be assumed to be copyable, but can be, depending on the specific type
Though it may seem like this distinction calls for a different syntax, in practice, both non-copyable and maybe-copyable types share the fundamental requirement: the compiler cannot assume the type is copyable.
Case study: finding the longest line in a large file
To demonstrate the performance advantages of non-copyable types in Swift, let’s try a real-world, performance-critical task: finding the longest line in a large file. In cases where files are too large to load entirely into memory, we need to read them line by line. Optimizing tasks like this can yield significant benefits for performance, especially when processing multi-gigabyte files.
For our case study, we use a large dataset – 2,47GB of Github Commit Messages. The goal is to identify the longest line in the file as efficiently as possible.
Initial approach: using high-level Swift APIs
The following code sample demonstrates a possible typical wrapper around a FILE pointer:
public final class File {
private let file: UnsafeMutablePointer<FILE>
public init(fileURL: URL) throws {
guard let file = fopen(fileURL.path, "r") else {
throw NSError(
domain: NSPOSIXErrorDomain,
code: Int(errno),
userInfo: nil
)
}
self.file = file
}
deinit {
let success = fclose(file) == 0
assert(success)
}
}
And this code illustrates the readLine API that the File wrapper might expose.
public func readLine() throws -> String? {
var buffer = [CChar](repeating: 0, count: maxLength)
guard fgets(&buffer, Int32(maxLength), file) != nil else {
if feof(file) != 0 {
return nil
} else {
throw NSError(
domain: NSPOSIXErrorDomain,
code: Int(errno),
userInfo: nil
)
}
}
return String(cString: buffer)
}
Finally, we can implement an algorithm to find the longest line:
extension File {
public func findLongest() throws -> String? {
var longest: String? = nil
while let line: String = try readLine() {
if line.count > (longest?.count ?? 0) {
longest = line
}
}
return longest
}
}
Running this code on a large file won’t complete in a reasonable amount of time. Before we optimize it, we want to check the instruments trace:

We can see that over 90% of the time is spent in functions related to String handling, which is somewhat expected. Swift’s Strings are very powerful, but that power comes at a cost.
Ideally, we’d want to see file reading operations at the top of the profile.
Optimization #1: using the CChar array instead of String
Instead of constructing a String for every line that we read, let’s expose the [CChar] array as a return type of readLine and construct a String only when we have a result:
func findLongest() throws -> String? {
var longest: [CChar]? = nil
var longestCount: Int = 0
while let line: [CChar] = try readLine() {
let count = line.withUnsafeBufferPointer { strlen($0.baseAddress!) }
if count > longestCount {
longest = line
longestCount = count
}
}
return longest.map { String(cString: $0) }
Let’s see how it performs now.
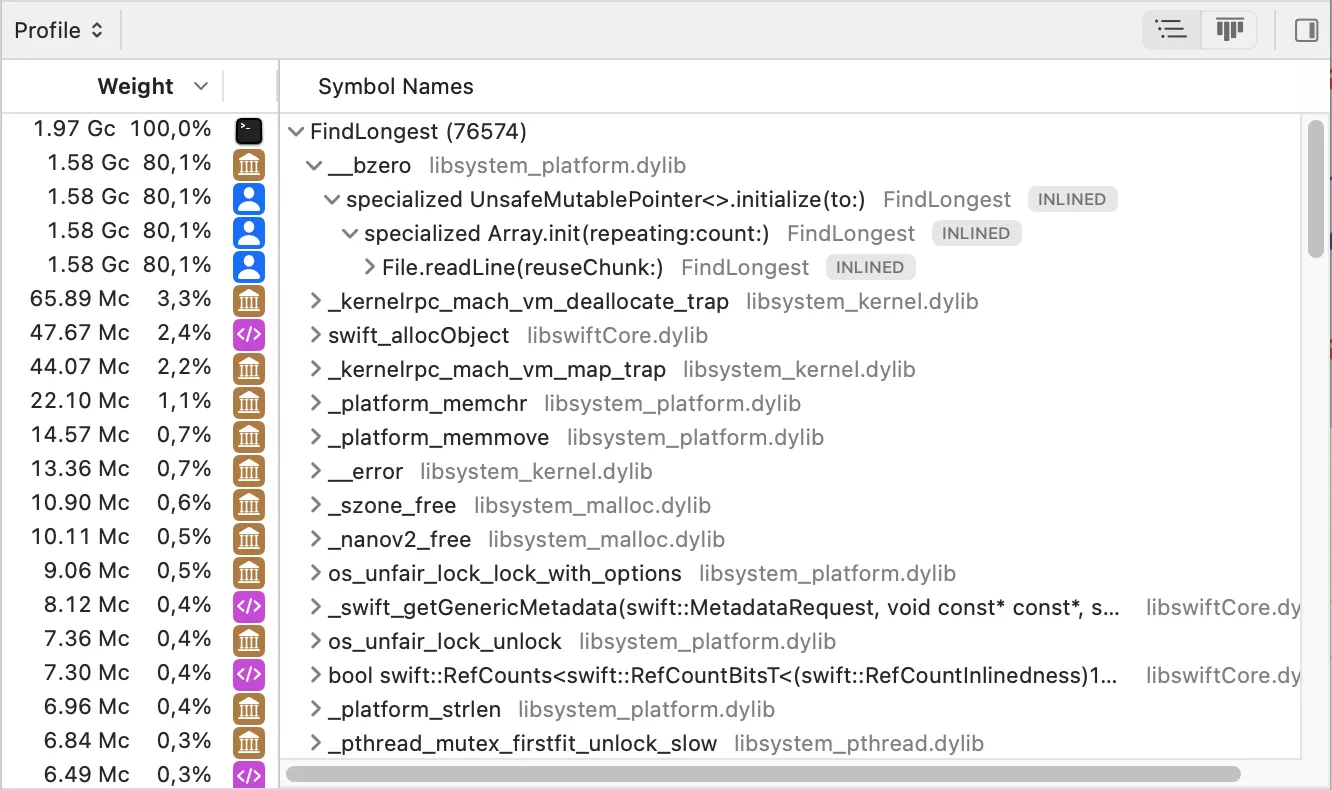
This change eliminates much of the overhead associated with String creation, but performance is still impacted by the memory allocations for each line. This is expected, as we are allocating a new buffer for each line read.
Optimization #2: reusing existing buffers
Let’s reuse a buffer from the previous read iteration instead of allocating a new one every time:
func findLongest() throws -> String? {
var buffer = [CChar](repeating: 0, count: maxLength)
var longest: [CChar]? = nil
var longestCount: Int = 0
while let line: [CChar] = try readLine(reuseChunk: &buffer) {
let count = line.withUnsafeBufferPointer { strlen($0.baseAddress!) }
if count > longestCount {
longest = line
longestCount = count
}
}
return longest.map { String(cString: $0) }
}
If we profile this code, we get the following trace:
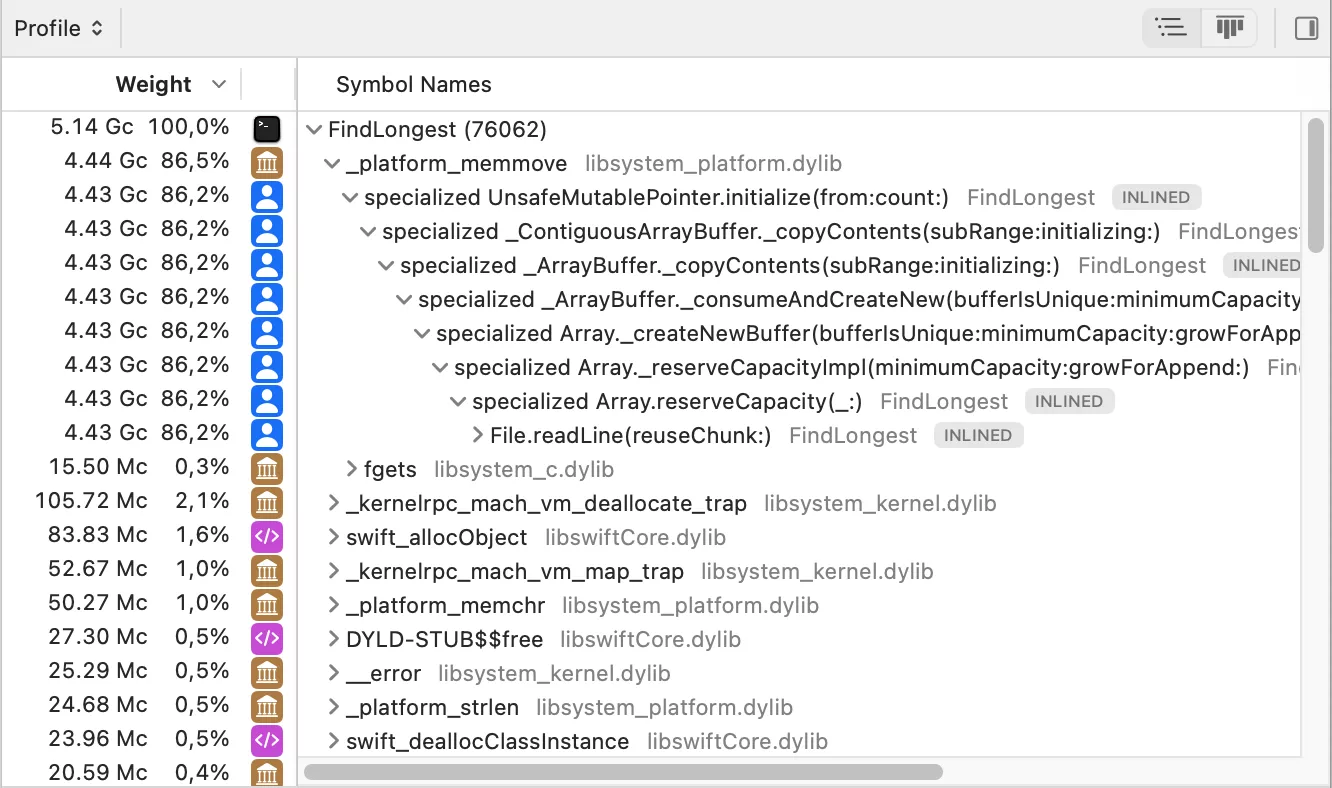
This reduces the memory allocation cost but surfaces a new issue: the Array type in Swift is a copy-on-write (CoW) data type, and whenever we find a new longest line, the whole array will be copied.
Optimization #3: introducing FileChunk
To avoid unnecessary copying, we will not expose [CChar] directly but wrap a pointer in a FileChunk object:
public final class FileChunk {
private let maxCount: Int
let _buffer: UnsafeMutablePointer<CChar>
init(maxCount: Int) {
precondition(maxCount > 0)
self.maxCount = maxCount
_buffer = UnsafeMutablePointer<CChar>.allocate(capacity: maxCount)
_buffer.initialize(repeating: 0, count: maxCount)
}
deinit {
_buffer.deinitialize(count: maxCount)
_buffer.deallocate()
}
public var count: Int { strlen(_buffer) }
public var asString: String { String(cString: _buffer) }
}
This is our findLongest algorithm now:
func findLongest() throws -> String? {
var buffer = FileChunk(maxLength: maxLength)
var longest: FileChunk? = nil
var longestCount: Int = 0
while let line: FileChunk = try readLine(reuseChunk: &buffer) {
let count = line.count
if count > longestCount {
longest = line
longestCount = count
}
}
return longest.asString
}
Let’s profile it now:
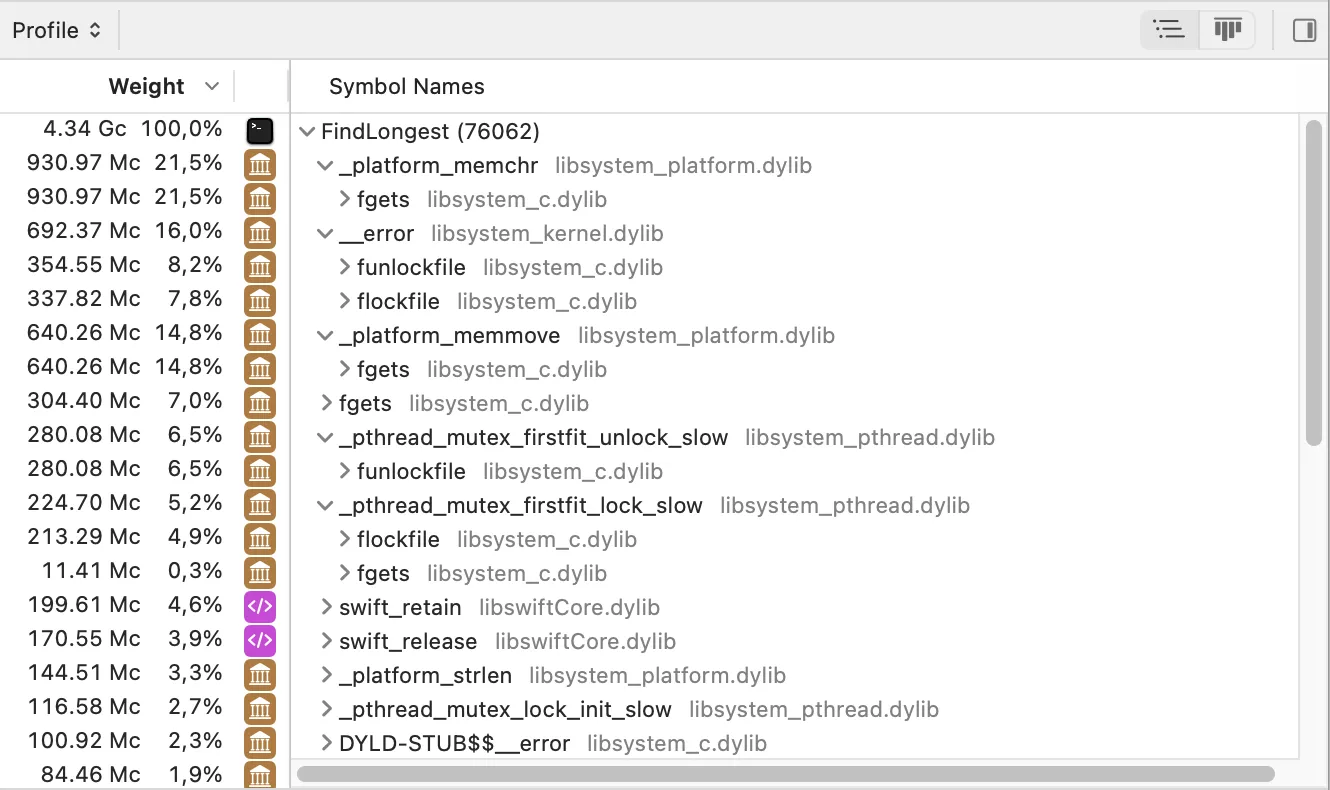
The situation is looking much better. As we would expect, the majority of the time is spent on fgets and the associated C functions.
It is also interesting to notice that swift_retain and swift_release incur significant costs.
Optimization #4: making FileChunk non-copyable
To address this issue, we’ll convert FileChunk from a reference type to a non-copyable type:
public struct FileChunk: ~Copyable {
// the same implementation
}
But now we are required to explicitly manage the ownership of FileChunk as it can no longer be shared between multiple owners.
First, we need to adjust our readLine function to make ownership explicit:
func readLine(toReuse: consuming FileChunk? = nil) throws -> FileChunk? {
let currentChunk = toReuse ?? FileChunk(maxCount: maxLength)
// The same implementation as previously
return currentChunk
}
In this version, we mark the FileChunk parameter as consuming, meaning the function takes ownership of the argument. Once the buffer is filled, the function returns currentChunk, passing ownership back to the caller, allowing the buffer to be reused.
After making this change, we get two errors in our findLongest implementation:
func findLongest() throws -> String? {
var longest: FileChunk? = nil
var buffer = FileChunk(maxCount: maxLength) ❌ // 'buffer' consumed in a loop
var longestCount: Int = 0
while let line: FileChunk = try readLine(toReuse: buffer) {
let count = line.count
if count > longestCount {
longest = line ❌ // Implicit conversion to 'FileChunk?' is consuming
longestCount = count
}
}
return longest?.asString
}
Let’s solve them:
func findLongest() throws -> String? {
var longest: FileChunk? = nil
var buffer = FileChunk(maxCount: maxLength)
var longestCount: Int = 0
while let line: FileChunk = try readLine(toReuse: buffer) {
let count = line.count
if count > longestCount {
buffer = longest
longest = consume line
longestCount = count
} else {
buffer = consume line
}
}
return longest?.asString
}
And now, let’s check the performance.
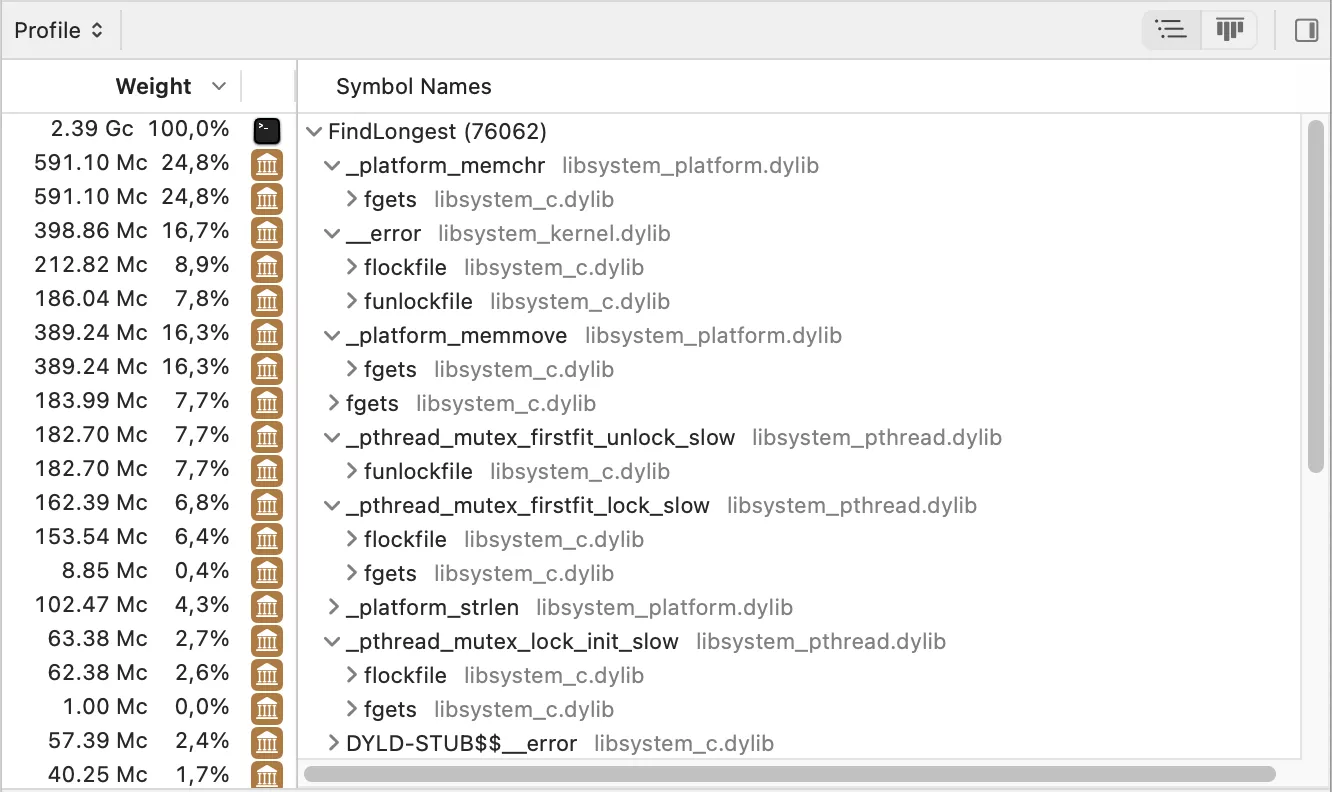
We can see that almost all of the time is spent on file reading operations, indicating a significant performance improvement.
Final results: performance gains
The performance improvements across the different implementations are summarized in the table below:
| Implementation | Timing (ms) |
|---|---|
| Naive | Doesn’t complete in reasonable time |
| CChar array | 106295 |
| Reuse allocation in CChar array | 100463 |
| FileChunk | 3136 |
| Non-copyable FileChunk | 2079 |
Note: If you are interested, the longest line can be found in this commit.
A hidden bug
If you look closely, you’ll notice a difference between our final implementation using a reference type and the one using a non-copyable type:
FileChunk as a reference type
<code>let count = line.count
if count > longestCount {
longest = line
longestCount = count
}</code>
FileChunk as a non-copyable type
<code>let count = line.count
if count > longestCount {
buffer = longest
longest = consume line
longestCount = count
} else {
buffer = consume line
}</code>
Upon closer inspection, we can see that the reference type implementation contains a hidden bug – it overrides the longest line found because the buffer is being reused. This issue is avoided with the non-copyable type, as it enforces unique ownership and prevents unintentional buffer reuse.
The value of non-copyable types
As we’ve seen, non-copyable types offer not only performance benefits but also improved safety compared to reference types. They are a safer and more ergonomic alternative to dealing with raw pointers.
One of the reasons the programming language C is known for its speed is that it exposes the full complexity of memory management, allowing direct manipulation through pointers. Swift, as a high-level programming language, abstracts much of this complexity. With the introduction of non-copyable types, Swift strikes a balance – allowing developers to write safe, high-performance code while maintaining the high-level programming experience.
For reference, the associated source code for this article can be found here.



